This part describes the implementation of the feature-finding algorithm. The core of the algorithm is described in the MaxQuant-Paper. The supplementary material explains the underlying methodology in great detail and is the foundation of the theoretical background that is described here. A refined version of the algorithm was presented with Dinosaur, which was also used as a reference for the Python implementation.
For the algorithm, we need serval modules:
Connecting Centroids to Hills
Refinement of Hills
Calculating Hill Statistics
Combining Hills to Isotope Patterns
Deconvolution of Isotope Patterns
Loading Data
From the IO library, we already have an *.ms_data.hdf container that contains centroided data. To use it in feature finding, we directly load the data.
Connecting Centroids to Hills
Note
Feature finding relies heavily on the performance function decorator from the performance notebook: @alphapept.performance.performance_function. Part of this is that the functions will not have return values to be GPU compatible. Please check out this notebook for further information.
Connecting centroids
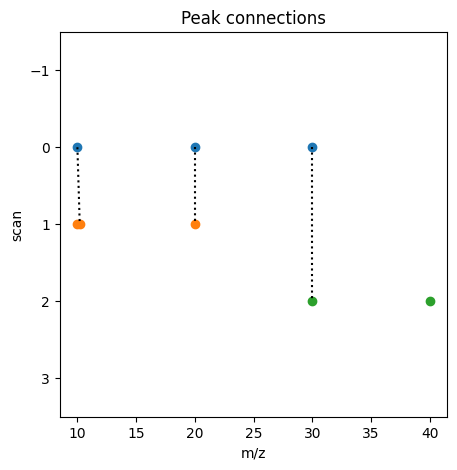
Feature finding starts with connecting centroids. For this we look at subsequent scans and compare peaks that are withing a defined mass tolerance (centroid_tol).
Imagine you have three scans with the following centroids:
Scan 0: 10, 20, 30
Scan 1: 10.2, 40.1
Scan 2: 40, 50, 60
When comparing consecutive scans and defining the maximum delta mass to be 0.5 find the following connections: (Scan No, Centroid No) -> (Scan No, Centroid No). As we cannot easily store tuples in the matrix, we convert tuple containing the position of the connected centroid to an integer. * (0,0) -> (1,0) -> (3): 10 & 10.2 -> delta = 0.2 * (1,1) -> (2,0) -> (6): 40.1 & 40 -> delta = 0.1
This allows us to not only easily store connections between centroids but also perform a quick lookup for the delta of an existing connection. Note that it also only stores the best connection for each centroid. To extract the connected centroids, we can use np.where(results >= 0). This implementation allows getting millions of connections within seconds.
As we are also allowing gaps, refering to that we can have connections between Scan 0 and Scan 2, we make the aforementioned matrix multdimensional, so that e.g. a first matrix stores the conncetions for no gap, the second matrix the connections with a gap of 1.
Wrapper function to call connect_centroids_unidirection
Args: rowwise_peaks (np.ndarray): Length of centroids with respect to the row borders. row_borders (np.ndarray): Row borders of the centroids array. centroids (np.ndarray): Array containing the centroids data. max_gap (int): Maximum gap when connecting centroids. centroid_tol (float): Centroid tolerance.
Args: x (np.ndarray): Index to datapoint. Note that this using the performance_function, so one passes an ndarray. row_borders (np.ndarray): Row borders of the centroids array. connections (np.ndarray): Connections matrix to store the connections scores (np.ndarray): Score matrix to store the connections centroids (np.ndarray): 1D Array containing the masses of the centroids data. max_gap (int): Maximum gap when connecting centroids. centroid_tol (float): Centroid tolerance.
We wrap the centroid connections in the function connect_centroids. This function converts the connections into an usable array.
Args: rowwise_peaks (np.ndarray): Indexes for centroids. row_borders (np.ndarray): Row borders (for indexing). centroids (np.ndarray): Centroid data. max_gap: Maximum gap. centroid_tol: Centroid tol for matching centroids. Returns: np.ndarray: From index. np.ndarray: To index. float: Median score. float: Std deviation of the score.
Args: x (np.ndarray): Input index. Note that we are using the performance function so this is a range. from_idx (np.ndarray): From index. to_idx (np.ndarray): To index.
Convert integer indices of a matrix to coordinates.
Args: x (np.ndarray): Input index. Note that we are using the performance function so this is a range. from_r (np.ndarray): From array with row coordinates. from_c (np.ndarray): From array with column coordinates. to_r (np.ndarray): To array with row coordinates. to_c (np.ndarray): To array with column coordinates. row_borders (np.ndarray): Row borders (for indexing). out_from_idx (np.ndarray): Reporting array: 1D index from. out_to_idx (np.ndarray): Reporting array: 1D index to.
Args: query_data (dict): Data structure containing the query data. max_gap (int): Maximum gap when connecting centroids. centroid_tol (float): Centroid tolerance.
Returns: hill_ptrs (np.ndarray): Array containing the bounds to the hill_data. hill_data (np.ndarray): Array containing the indices to hills. path_node_cnt (int): Number of elements in this path. score_median (float): Median score. score_std (float): Std deviation of the score.
Args: centroids (np.ndarray): 1D Array containing the masses of the centroids. from_idx (np.ndarray): From index. to_idx (np.ndarray): To index. hill_length_min (int): Minimum hill length:
Returns: hill_ptrs (np.ndarray): Array containing the bounds to the hill_data. hill_data (np.ndarray): Array containing the indices to hills. path_node_cnt (int): Number of elements in this path.
Args: x (np.ndarray): Input index. Note that we are using the performance function so this is a range. path_starts (np.ndarray): Array that stores the starts of the paths. forwards (np.ndarray): Forward array. out_hill_data (np.ndarray): Array containing the indices to hills. out_hill_ptr (np.ndarray): Array containing the bounds to out_hill_data.
Args: x (np.ndarray): Input index. Note that we are using the performance function so this is a range. path_starts (np.ndarray): Array that stores the starts of the paths. forward (np.ndarray): Array that stores forward information. path_cnt (np.ndarray): Reporting array to count the paths.
Args: x (np.ndarray): Input index. Note that we are using the performance function so this is a range. forward (np.ndarray): Array to report forward connection. backward (np.ndarray): Array to report backward connection. path_starts (np.ndarray): Array to report path starts.
Extracts path information and writes to path matrix.
Args: x (np.ndarray): Input index. Note that we are using the performance function so this is a range. from_idx (np.ndarray): Array containing from indices. to_idx (np.ndarray): Array containing to indices. forward (np.ndarray): Array to report forward connection. backward (np.ndarray): Array to report backward connection.
Hill Splitting
When having a hill with two or more maxima, we would like to split it at the minimum position. For this, we use a recursive approach. First, the minimum of a hill is detected. A hill is split at this minimum if the smaller of the surrounding maxima is at least the factor hill_split_level larger than the minimum. For each split, the process is repeated.
Args: hill_ptrs (np.ndarray): Array containing the bounds to the hill_data. hill_data (np.ndarray): Array containing the indices to hills. int_data (np.ndarray): Array containing the intensity to each centroid. hill_split_level (float): Split level for hills. window (int): Smoothing window.
Returns: np.ndarray: Array containing the bounds to the hill_data with splits.
Args: k (np.ndarray): Input index. Note that we are using the performance function so this is a range. hill_ptrs (np.ndarray): Array containing the bounds to the hill_data. int_data (np.ndarray): Array containing the intensity to each centroid. hill_data (np.ndarray): Array containing the indices to hills. splits (np.ndarray): Array containing splits. hill_split_level (float): Split level for hills. window (int): Smoothing window.
Filter Hills
To filter hills, we define a minimum length hill_min_length. All peaks below the threshold hill_peak_min_length are accepted as is. For longer hills, the intensity at the start and the end are compared to the maximum intensity. If the ratio of the maximum raw intensity to the smoothed intensity and the beginning and end are larger than hill_peak_factor the hills are accepted.
Args: hill_data (np.ndarray): Array containing the indices to hills. hill_ptrs (np.ndarray): Array containing the bounds to the hill_data. int_data (np.ndarray): Array containing the intensity to each centroid. hill_check_large (int, optional): Length criterion when a hill is considered large.. Defaults to 40. window (int, optional): Smoothing window. Defaults to 1.
Returns: np.ndarray: Filtered hill data. np.ndarray: Filtered hill points.
Function to check large hills and flag them for removal.
Args: idx (np.ndarray): Input index. Note that we are using the performance function so this is a range. large_peaks (np.ndarray): Array containing large peaks. hill_ptrs (np.ndarray): Array containing the bounds to the hill_data. hill_data (np.ndarray): Array containing the indices to hills. int_data (np.ndarray): Array containing the intensity to each centroid. to_remove (np.ndarray): Array with indexes to remove. large_peak (int, optional): Length criterion when a peak is large. Defaults to 40. hill_peak_factor (float, optional): Hill maximum criterion. Defaults to 2. window (int, optional): Smoothing window.. Defaults to 1.
Since the mass estimate min the equation above is more complicated than just an average of the mj, a standard deviation based estimate of the error would not be appropriate. Therefore we calculate the error as a bootstrap2 estimate over B=150 bootstrap replications
Calculating Hill Statistics
Next, we calculate summary statistics for the connected centroids. We can obtain a high precision mass estimate for each hill by taking the average of the the masses and weighting this by their intensiteis:
The calculation of hill statistics for a single hill is implemented in get_hill_stats. To calculate the hill stats for a list of hills, we can call the wrapper get_hill_data.
Args: query_data (dict): Data structure containing the query data. hill_ptrs (np.ndarray): Array containing the bounds to the hill_data. hill_data (np.ndarray): Array containing the indices to hills. hill_nboot_max (int): Maximum number of bootstrap comparisons. hill_nboot (int): Number of bootstrap comparisons
Returns: np.ndarray: Hill stats. np.ndarray: Sortindex. np.ndarray: Upper index. np.ndarray: Scan index. np.ndarray: Hill data. np.ndarray: Hill points.
Args: stats (np.ndarray): Stats array that contains summary statistics of hills. hill_data (np.ndarray): Array containing the indices to hills. hill_ptrs (np.ndarray): Array containing the bounds to the hill_data.
Returns: np.ndarray: Filtered hill data. np.ndarray: Filtered hill points. np.ndarray: Filtered hill stats.
Args: idx (np.ndarray): Input index. Note that we are using the performance function so this is a range. hill_range (np.ndarray): Hill range. hill_ptrs (np.ndarray): Array containing the bounds to the hill_data. hill_data (np.ndarray): Array containing the indices to hills. int_data (np.ndarray): Array containing the intensity to each centroid. mass_data (np.ndarray): Array containing mass data. rt_ (np.ndarray): Array with retention time information for each scan. rt_idx (np.ndarray): Lookup array to match centroid idx to rt. stats (np.ndarray): Stats array that contains summary statistics of hills. hill_nboot_max (int): Maximum number of bootstrap comparisons. hill_nboot (int): Number of bootstrap comparisons
Combining Hills to Isotope Patterns
After obtaining summary statistics of hills, the next step is to check whether they belong together to form an isotope pattern. For this, we check wheter it is possible that they are neighbors in an isotope pattern, e.g. one having a 12C atom that has been replaced by a 13C version. The detailed criterion for the check is implemented in check_isotope_pattern and is as follows:
The left side contains \(\Delta m\), being the delta of the precise mass estimates from the summary statistics and \(\Delta M = 1.00286864\), which is the mass difference ebtween the 13C peak and the monoisotopic peak in an averagine molecule of 1500 Da mass divided by the charge \(z\).
The right side contains \(\Delta S = 0.0109135\), which is the maximum shift that a sulphur atom can cause (\(\Delta S = 2m(^{13}C) - 2m(^{12}C) - m(^{34}S) + m(^{32}S)\)) and \(\Delta {m_{1}}\) and \(\Delta {m_{2}}\), which are the bootstrapped mass standard deviations.
Check if two masses could belong to the same isotope pattern.
Args: mass1 (float): Mass of the first pattern. mass2 (float): Mass of the second pattern. delta_mass1 (float): Delta mass of the first pattern. delta_mass2 (float): Delta mass of the second pattern. charge (int): Charge. iso_mass_range (int, optional): Mass range. Defaults to 5.
Returns: bool: Flag to see if pattern belongs to the same pattern.
An additional criterion that is being checked is that the intensity profiles have sufficient overalp in retention time. This is validated by ensuring that two hills have a cosine correlation of at least 0.6.
The intensities of two hills are only compared if both have an intensity value in a particular scan. Otherwise, the intensity is set to zero. Additionally, an overlap of at least three elements is required.
Args: scans_ (np.ndarray): Masses of the first scan. scans_2 (np.ndarray): Masses of the second scan. int_ (np.ndarray): Intensity of the first scan. int_2 (np.ndarray): Intensity of the second scan.
Returns: float: Correlation.
Extracting pre-Isotope Patterns
Now having two criteria to check whether hills could, in principle, belong together, we define the wrapper functions extract_edge and get_edges to extract the connected hills. To minimize the number of comparisons we need to perform, we only compare the hills that overlap in time (i.e., the start of one hill rt_min needs to be before the end of the other hill rt_max) and are less than the sum of \(\Delta M\) and \(\Delta S\) apart.
To extract all hills that belong together, we again rely on the NetworkX-package to extract the connected components.
Correlates two edges and flag them it they should be kept.
Args: idx (np.ndarray): Input index. Note that we are using the performance function so this is a range. to_keep (np.ndarray): Array with indices which edges should be kept. sortindex_ (np.ndarray): Sortindex to access the hills from stats. pre_edges (np.ndarray): Array with pre edges. hill_ptrs (np.ndarray): Array containing the bounds to the hill_data. hill_data (np.ndarray): Array containing the indices to hills. int_data (np.ndarray): Array containing the intensity to each centroid. scan_idx (np.ndarray): Array containing the scan index for a centroid. cc_cutoff (float): Cutoff value for what is considered correlating.
Args: stats (np.ndarray): Stats array that contains summary statistics of hills. idxs_upper (np.ndarray): Upper index for comparison. sortindex_ (np.ndarray): Sortindex to access the hills from stats. hill_ptrs (np.ndarray): Array containing the bounds to the hill_data. hill_data (np.ndarray): Array containing the indices to hills. int_data (np.ndarray): Array containing the intensity to each centroid. scan_idx (np.ndarray): Array containing the scan index for a centroid. maximum_offset (float): Maximum offset when matching. iso_charge_min (int, optional): Minimum isotope charge. Defaults to 1. iso_charge_max (int, optional): Maximum isotope charge. Defaults to 6. iso_mass_range (float, optional): Mass search range. Defaults to 5. cc_cutoff (float, optional): Correlation cutoff. Defaults to 0.6.
Returns: list: List of pre isotope patterns.
Extracting Isotope Patterns
The extracted pre-isotope patterns may not be consistent because their pair-wise mass differences may not correspond to the same charge. To extract isotope patterns from pre-isotope patterns, we need to ensure that they are consistent for a single charge.
To do this, we start with the 100 most intense peaks from a pre-isotope pattern to be used as a seed. For each seed and charge we then try to extract the longest consistent isotope pattern. To check wheter a hill is consistent with the seed we employ a modified checking criterion (check_isotope_pattern_directed) to be as follows:
Here \(m\) is the mass of a seed peak, and \(m_{j}\) refers to a peak relative to the seed. \(j\) refers to the peaks to the left or right (negative or positive index) within the pattern. \(j\) needs to run over consecutive values so that gaps are not allowed. Besides this consistency check, two hills are also checked to have a cosine correlation of at least 0.6.
Programmatically, this is implemented in grow_trail and grow. These function uses a recursive approach that adds matching hills to the seed on the left and right side until no more hills can be added.
Wrapper to extract trails for a given charge range.
Args: seed (int): Seed index. pattern (np.ndarray): Pre isotope pattern. stats (np.ndarray): Stats array that contains summary statistics of hills. charge_range (List): Charge range. iso_mass_range (float): Mass range for checking isotope patterns. sortindex_ (np.ndarray): Sortindex to access the hills from stats. hill_ptrs (np.ndarray): Array containing the bounds to the hill_data. hill_data (np.ndarray): Array containing the indices to hills. int_data (np.ndarray): Array containing the intensity to each centroid. scan_idx (np.ndarray): Array containing the scan index for a centroid. cc_cutoff (float): Cutoff value for what is considered correlating.
Wrapper to grow an isotope pattern to the left and right side.
Args: seed (int): Seed position. pattern (np.ndarray): Isotope pattern. stats (np.ndarray): Stats array that contains summary statistics of hills. charge (int): Charge. iso_mass_range (float): Mass range for checking isotope patterns. sortindex_ (np.ndarray): Sortindex to access the hills from stats. hill_ptrs (np.ndarray): Array containing the bounds to the hill_data. hill_data (np.ndarray): Array containing the indices to hills. int_data (np.ndarray): Array containing the intensity to each centroid. scan_idx (np.ndarray): Array containing the scan index for a centroid. cc_cutoff (float): Cutoff value for what is considered correlating.
Grows isotope pattern based on a seed and direction.
Args: trail (List): List of hills belonging to a pattern. seed (int): Seed position. direction (int): Direction in which to grow the trail relative_pos (int): Relative position. index (int): Index. stats (np.ndarray): Stats array that contains summary statistics of hills. pattern (np.ndarray): Isotope pattern. charge (int): Charge. iso_mass_range (float): Mass range for checking isotope patterns. sortindex_ (np.ndarray): Sortindex to access the hills from stats. hill_ptrs (np.ndarray): Array containing the bounds to the hill_data. hill_data (np.ndarray): Array containing the indices to hills. int_data (np.ndarray): Array containing the intensity to each centroid. scan_idx (np.ndarray): Array containing the scan index for a centroid. cc_cutoff (float): Cutoff value for what is considered correlating.
Returns: List: List of hills belonging to a pattern.
Check if two masses could belong to the same isotope pattern.
Args: mass1 (float): Mass of the first pattern. mass2 (float): Mass of the second pattern. delta_mass1 (float): Delta mass of the first pattern. delta_mass2 (float): Delta mass of the second pattern. charge (int): Charge. index (int): Index (unused). iso_mass_range (float): Isotope mass ranges. Returns: bool: Flag if two isotope patterns belong together.
Args: pattern (np.ndarray): Pre isotope pattern. sorted_hills (np.ndarray): Hills, sorted. centroids (np.ndarray): 1D Array containing the masses of the centroids. hill_data (np.ndarray): Array containing the indices to hills.
Function to get a list of minima in a trace. A minimum is returned if the ratio of lower of the surrounding maxima to the minimum is larger than the splitting factor.
Args: y (np.ndarray): Input array. iso_split_level (float): Isotope split level.
Returns: List: List with min positions.
Isolating Isotope_patterns
The extraction of the longest consistent isotope pattern is implemented in isolate_isotope_pattern. Here, three additional checks for an isotope pattern are implemented.
The first one is truncate. Here, one checks the seed position, whether it has a minimum to its left or right side. If a minimum is found, the isotope pattern is cut off at this position.
The second one is a mass filter. If the seed has a mass of smaller than 1000, the intensity maximum is detected, and all smaller masses are discarded. This reflects the averagine distribution for small masses where no minimum on the left side can be found.
The third one is check_averagine that relies on pattern_to_mz and cosine_averagine. It is used to ensure that the extracted isotope pattern has a cosine correlation of the averagine isotope pattern of the same mass of at least 0.6.
After the longest consistent isotope pattern is found, the hills are removed from the pre-isotope pattern, and the process is repeated until no more isotope patterns can be extracted from the pre-isotope patterns.
Args: int_one (np.ndarray): Intensity of the first hill. int_two (np.ndarray): Intensity of the second hill. spec_one (np.ndarray): Scan numbers of the first hill. spec_two (np.ndarray): Scan numbers of the second hill.
Args: pre_pattern (np.ndarray): Pre isotope pattern. hill_ptrs (np.ndarray): Array containing the bounds to the hill_data. hill_data (np.ndarray): Array containing the indices to hills. int_data (np.ndarray): Array containing the intensity to each centroid. scan_idx (np.ndarray): Array containing the scan index for a centroid. stats (np.ndarray): Stats array that contains summary statistics of hills. sortindex_ (np.ndarray): Sortindex to access the hills from stats. iso_mass_range (float): Mass range for checking isotope patterns. charge_range (List): Charge range. averagine_aa (Dict): Dict containing averagine masses. isotopes (Dict): Dict containing isotopes. iso_n_seeds (int): Number of seeds. cc_cutoff (float): Cutoff value for what is considered correlating. iso_split_level (float): Split level when isotopes are split.
Returns: np.ndarray: Array with the best pattern. int: Charge of the best pattern.
Wrapper function to iterate over pre_isotope_patterns.
Args: pre_isotope_patterns (list): List of pre-isotope patterns. hill_ptrs (np.ndarray): Array containing the bounds to the hill_data. hill_data (np.ndarray): Array containing the indices to hills. int_data (np.ndarray): Array containing the intensity to each centroid. scan_idx (np.ndarray): Array containing the scan index for a centroid. stats (np.ndarray): Stats array that contains summary statistics of hills. sortindex_ (np.ndarray): Sortindex to access the hills from stats. averagine_aa (Dict): Dict containing averagine masses. isotopes (Dict): Dict containing isotopes. iso_charge_min (int, optional): Minimum isotope charge. Defaults to 1. iso_charge_max (int, optional): Maximum isotope charge. Defaults to 6. iso_mass_range (float, optional): Mass search range. Defaults to 5. iso_n_seeds (int, optional): Number of isotope seeds. Defaults to 100. cc_cutoff (float, optional): Cuttoff for correlation.. Defaults to 0.6. iso_split_level (float, optional): Isotope split level.. Defaults to 1.3. callback (Union[Callable, None], optional): Callback function for progress. Defaults to None. Returns: list: List of isotope patterns. np.ndarray: Iso idx. np.ndarray: Array containing isotope charges.
Function to extract summary statstics from a list of isotope patterns and charges.
MS1 feature intensity estimation. For each isotope envelope we interpolate the signal over the retention time range. All isotope enevelopes are summed up together to estimate the peak sahpe
Lastly, we report three estimates for the intensity:
ms1_int_sum_apex: The intensity at the peak of the summed signal.
ms1_int_sum_area: The area of the summed signal
ms1_int_max_apex: The intensity at the peak of the most intense isotope envelope
ms1_int_max_area: The area of the the most intense isotope envelope
Args: idx (np.ndarray): Input index. Note that we are using the performance function so this is a range. isotope_patterns (list): List containing isotope patterns (indices to hills). isotope_charges (list): List with charges assigned to the isotope patterns. iso_idx (np.ndarray): Index to isotope pattern. stats (np.ndarray): Stats array that contains summary statistics of hills. sortindex_ (np.ndarray): Sortindex to access the hills from stats. hill_ptrs (np.ndarray): Array containing the bounds to the hill_data. hill_data (np.ndarray): Array containing the indices to hills. int_data (np.ndarray): Array containing the intensity to each centroid. rt_ (np.ndarray): Array with retention time information for each scan. rt_idx (np.ndarray): Lookup array to match centroid idx to rt. results (np.ndarray): Recordarray with isotope pattern summary statistics. lookup_idx (np.ndarray): Lookup array for each centroid.
Creates a report dataframe with summary statistics of the found isotope patterns.
Args: query_data (dict): Data structure containing the query data. isotope_patterns (list): List containing isotope patterns (indices to hills). isotope_charges (list): List with charges assigned to the isotope patterns. iso_idx (np.ndarray): Index to the isotope pattern. stats (np.ndarray): Stats array that contains summary statistics of hills. sortindex_ (np.ndarray): Sortindex to access the hills from stats. hill_ptrs (np.ndarray): Array containing the bounds to the hill_data. hill_data (np.ndarray): Array containing the indices to hills.
Returns: pd.DataFrame: DataFrame with isotope pattern summary statistics.
Data Output
For each feature that is found we extract summary statistics and put it in tabular form to be used as as pandas dataframe.
Plotting
For quality control reasons we also employ a function to plot a feature in its local environment.
External Feature Finder
To utilize the command-line Feature Finder from Bruker 4DFF-3.13 - uff-cmdline2.exe, we call it via a subprocess and wait until completion.
Map Ms1 to Ms2 via Table FeaturePrecursorMapping from Bruker FF.
Args: feature_path (str): Path to the feature file from Bruker FF (.features-file). feature_table (pd.DataFrame): Pandas DataFrame containing the features. query_data (dict): Data structure containing the query data.
Returns: pd.DataFrame: DataFrame containing features information.
Args: file (str): Filename for feature finding. base_dir (str, optional): Base dir where the feature finder is stored.. Defaults to “ext/bruker/FF”. config (str, optional): Config file for feature finder. Defaults to “proteomics_4d.config”.
Raises: NotImplementedError: Unsupported operating system. FileNotFoundError: Feature finder not found. FileNotFoundError: Config file not found. FileNotFoundError: Feature file not found.
Args: to_process (tuple): to_process tuple, to be used from a proces spool. callback (Union[Callable, None], optional): Optional callback function. Defaults to None. parallel (bool, optional): Flag to use parallel processing. Currently unused. Defaults to False.
Raises: NotImplementedError: Error if the file extension is not understood.
Returns: Union[str, bool]: Returns true if function was sucessfull, otherwise the exception as string.
Map MS1 features to MS2 based on rt and mz. If ccs is included also add. Args: feature_table (pd.DataFrame): Pandas DataFrame with features. query_data (dict): Data structure containing the query data. map_mz_range (float, optional): Mapping range for mz (Da). Defaults to 1. map_rt_range (float, optional): Mapping range for rt (min). Defaults to 0.5. map_mob_range (float, optional): Mapping range for mobility (%). Defaults to 0.3. map_n_neighbors (int, optional): Maximum number of neighbors to be extracted. Defaults to 5. search_unidentified (bool, optional): Flag to perform search on features that have no isotope pattern. Defaults to False.