Scientific visualizations with alphapepttools#
In this tutorial, we will explore alphapepttools’ plotting functionalities. It is built inspired by the stylia package, and relies on two key principles:
Use matplotlib
FigureandAxesdirectly wherever possible, which enables users to extend thealphapepttoolscore plots with their own visualizations, while benefiting from the unified styling and coloring - this will make your figures and panels look like they are ‘cut from the same cloth’ rather than a patchwork of slightly different layouts.Follow modular design: Instead of making highly complex, increasingly large ‘does-everything’ methods (e.g. a volcanoplot that performs filtering, ttest, labelling and visualization all at once),
alphapepttoolsrelies on the separation of concerns, leading to significantly smaller functions from which plots can be built in a LEGO-like principle, and where custom functionalities can easily be added.
We distinguish between Color Palettes and Colormaps: The former are finite lists of RGBA tuple colors, while the latter are a continuous gradients from which an arbitrary number of colors can be sampled. alphapepttools provides the following presets:
Single primary colors: Stylized versions of primary colors based on the Spectral colormap
Color palettes:
binary color palette: two colors for maximum separability (e.g. for a volcanoplot’s up- and downregulated points)
qualitative color palette: 9 colors to color different data levels (e.g. for different disease states or batches)
Colormaps:
sequential: A gradient to color numeric values (e.g. map a continuous variable in a UMAP)
diverging: A gradient with two distinct sides and a middle, to map numeric values around a center (e.g. in a heatmap)
–> Highly recommended read on a lot of the color choices presented below: https://www.fabiocrameri.ch/colourmaps/ in this, Fabio Crameri outlines the deceptive nature of some default colorscales used in science and gives perceptually uniform, color vision deficiency (CVD) friendly alternatives
%load_ext autoreload
%autoreload 2
import logging
import anndata as ad
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import string
import alphapepttools as apt
logging.basicConfig(level=logging.INFO)
Primary colors in alphapepttools#
The ‘spectral’ colorscale was used to obtain a set of distinct primary colors, all of which can be accessed via apt.pl.BaseColors.get(<colorname>).
base_colors = [
"red",
"lightgreen",
"blue",
"orange",
"yellow",
"lightred",
"green",
"lightorange",
"lightblue",
"grey",
"white",
"black",
]
apt.pl.show_rgba_color_list([apt.pl.BaseColors.get(base_color) for base_color in base_colors])

Scientific colors in alphapepttools#
Aside from primary colors, plots often require coloring in two or more levels in a distinct manner. The perceptually uniform colorscales of https://github.com/callumrollo/cmcrameri.git (cmcrameri package) are aesthetic while at the same time adhering to best practices for color vision deficiencies (CVDs) and greyscale readability.
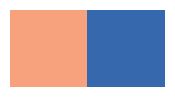
First, we introduce a simple binary palette, good for coloring ‘up-down’ type plots:#
# color palettes
apt.pl.show_rgba_color_list(apt.pl.BasePalettes.get("binary", 2))
Next, a qualitative colorscale is derived from cmcrameri’s batlow scale#
This palette is used by plots that assign different levels to colors. The colors are sampled at increments for maximum separability. Note that perceptual uniformity is not observed here, since these colors are meant for categorical levels, not representing numerical data.
apt.pl.show_rgba_color_list(apt.pl.BasePalettes.get("qualitative"))

A diverging colormap for heatmaps:#
apt.pl.show_rgba_color_list(list(apt.pl.BaseColormaps.get("diverging")(np.arange(0, 1, 0.001))))

A sequential colormap for quantitative data#
apt.pl.show_rgba_color_list(list(apt.pl.BaseColormaps.get("sequential")(np.arange(0, 1, 0.001))))

An important consideration for diverging data representation are extreme values: extreme outliers can squish the entire colormap into three values, making a potential heatmap less insightful. We can cap these colormaps by using the MappedColormaps functionality of the colors module:
test_data = [*list(np.random.rand(100)), -100, 100]
# map colormaps to numerical values without capping
mapped_colors = apt.pl.MappedColormaps(cmap="diverging", percentile=None).fit_transform(test_data)
apt.pl.show_rgba_color_list(mapped_colors)

# map colormaps to numerical values with capping between 5th and 95th percentile
mapped_colors = apt.pl.MappedColormaps(cmap="diverging", percentile=(5, 95)).fit_transform(data=test_data)
apt.pl.show_rgba_color_list(mapped_colors)

Generating plots#
alphapepttools wraps on matplotlib’s subplots() in its apt.pl.create_figure() method, with two important changes: First, instead of axes we return an instance of alphapepttools’ AxesManager which is a generator that returns subplots - while this might sound complicated on the surface, it is actually extremely easy:
fig, axm = apt.pl.create_figure(nrows=2, ncols=2)
Because axm is an AxisManager instance, we can hop from subplot to subplot by simply calling axm.next(). In the 2x2 panel indicated above, this amounts to row-wise steps. We can break the process down like this:
If we call:
ax = axm.next()
it takes us here in the subplots panel
X |
_ |
|---|---|
_ |
_ |
–> now, we are working with ax as we would: run alphapepttools plotting functions on it, or simply use matplotlib’s builtin functions like ax.scatter() and ax.bar(), etc. If we call
ax = axm.next()
again, ax is now this subplot:
_ |
X |
|---|---|
_ |
_ |
–> we can add another plot to it and continue with next() until we run out of panels.
Alternatively, we can access each subplot using indices like axm[2,1] to get here:
_ |
_ |
|---|---|
X |
_ |
But experience has shown that this is rarely ever needed - most of the time, simply calling .next() and working with the resulting axes object is more convenient!
It is much easier understood with an example, so try it yourself in the cell below!
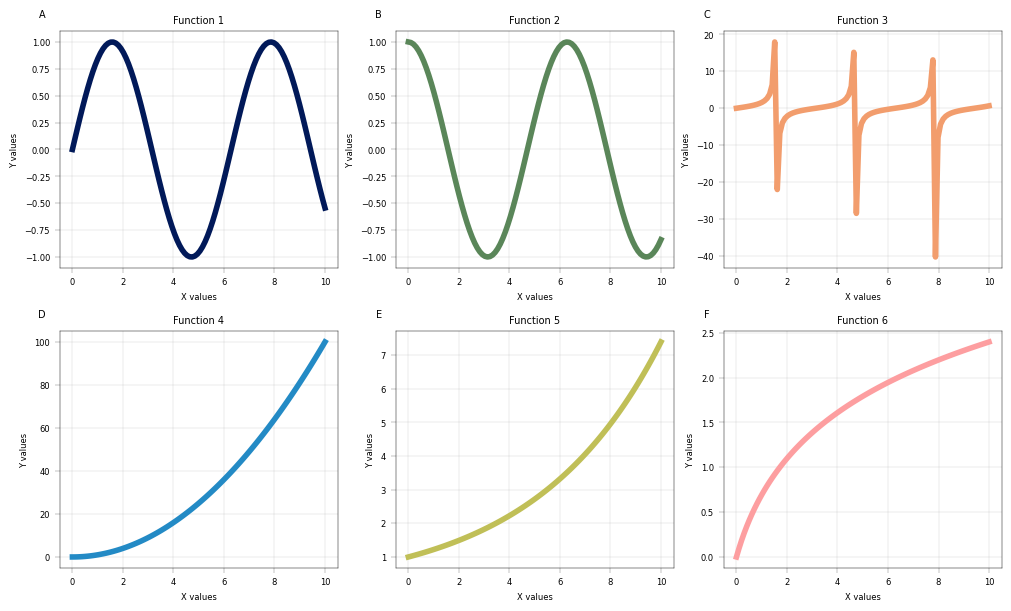
# Create a 2x3 grid of subplots. Return an instance of AxisManager
fig, axm = apt.pl.create_figure(nrows=2, ncols=3, figsize=(10, 6))
# Example dataset
x = np.linspace(0, 10, 100)
y_funcs = [
lambda x: np.sin(x),
lambda x: np.cos(x),
lambda x: np.tan(x),
lambda x: x**2,
lambda x: np.exp(x / 5),
lambda x: np.log(x + 1),
]
# Get qualitative palette, in this case use spectral
n_colors = len(y_funcs)
palette = apt.pl.BasePalettes.get("qualitative", n_colors)
# Iterate through all axes using next() and plot the different functions
for i, func in enumerate(y_funcs):
ax = axm.next()
# Use matplotlib's line plotting function
ax.plot(x, func(x), color=palette[i], lw=4)
# LEGO-principle: plotting and labelling are different functions, allowing us to combine
# matplotlib with alphapepttools' labelling function.
apt.pl.label_axes(
ax,
xlabel="X values",
ylabel="Y values",
title=f"Function {i + 1}",
enumeration=list(string.ascii_uppercase)[i], # add enumeration
)
plt.show()
# Save the figure
apt.pl.save_figure(
fig=fig,
filename="example_figure.png",
output_dir="./example_outputs",
dpi=300,
transparent=False,
)
Let’s make some more example data and showcase the remaining plots!#
# Set up reproducible random number generation
rng = np.random.default_rng(seed=42)
example_df = pd.DataFrame(
{
"values": np.concatenate([rng.normal(i, size=200) + rng.normal(i) for i in range(3)]),
"values2": np.concatenate([rng.normal(i, size=200) + rng.normal(i) for i in range(3)]),
"levels": [i for i in range(3) for _ in range(200)],
"levels2": np.arange(0, 600),
"levels3": [i for i in [1, 5, 30] for _ in range(200)],
}
)
example_df.index = example_df.index.astype(str)
# Introduce random NaN values into every column of example_df
for col in example_df.columns:
example_df.loc[example_df.sample(frac=0.05, random_state=rng.integers(0, 2**32 - 1)).index, col] = np.nan
example_adata = ad.AnnData(
X=example_df[["values", "values2"]].values,
obs=example_df[["levels", "levels2", "levels3"]],
var=example_df[["values", "values2"]].columns.to_frame(),
)
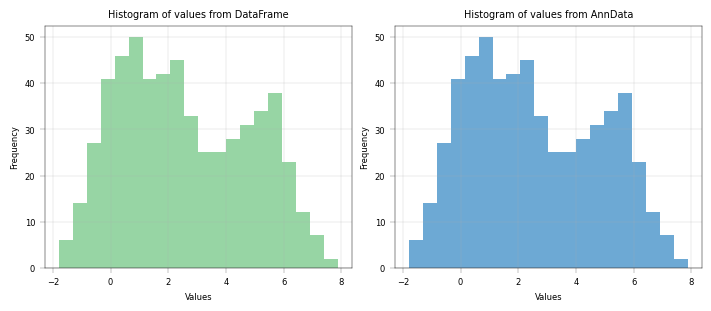
Basic histogram with dataframe and AnnData#
# with one color
fig, axm = apt.pl.create_figure(1, 2, figsize=(7, 3))
# Show histogram based on DataFrame
ax = axm.next()
apt.pl.histogram(
data=example_df,
value_column="values",
bins=20,
color="lightgreen",
ax=ax,
)
apt.pl.label_axes(ax, xlabel="Values", ylabel="Frequency", title="Histogram of values from DataFrame")
# Show histogram based on AnnData
ax = axm.next()
apt.pl.histogram(
data=example_adata,
value_column="values",
bins=20,
color="lightblue",
ax=ax,
)
apt.pl.label_axes(ax, xlabel="Values", ylabel="Frequency", title="Histogram of values from AnnData")
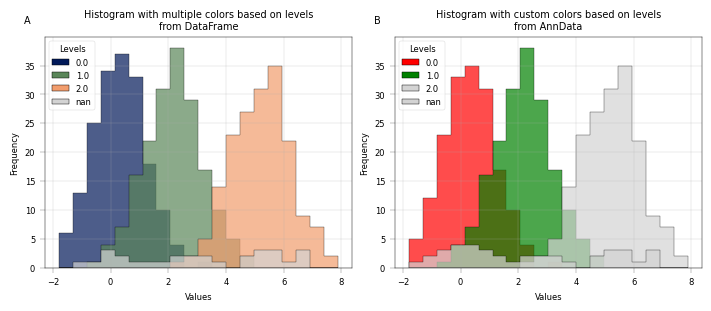
# with multiple colors based on levels
fig, axm = apt.pl.create_figure(1, 2, figsize=(7, 3))
# Show histogram based on DataFrame
ax = axm.next()
palette = apt.pl.BasePalettes.get("qualitative", example_df["levels"].nunique())
apt.pl.histogram(
data=example_df,
value_column="values",
color_map_column="levels",
palette=palette,
bins=20,
ax=ax,
legend="auto",
hist_kwargs={"alpha": 0.7, "histtype": "stepfilled", "edgecolor": "k"},
legend_kwargs={"title": "Levels", "loc": "upper left"},
)
apt.pl.label_axes(
ax,
xlabel="Values",
ylabel="Frequency",
title="Histogram with multiple colors based on levels\nfrom DataFrame",
enumeration="A",
)
ax = axm.next()
n_colors = example_adata.obs["levels"].nunique()
palette = apt.pl.BasePalettes.get("qualitative", n_colors)
# Introduce some nans
example_adata_copy = example_adata.copy()
example_adata_copy.obs.loc[example_adata_copy.obs.index[:10], "levels"] = np.nan
apt.pl.histogram(
data=example_adata_copy,
value_column="values",
color_map_column="levels",
palette=palette,
color_dict={"0.0": "red", "1.0": "green"}, # custom colors for specific levels, omit level 2
bins=20,
ax=ax,
legend="auto",
hist_kwargs={"alpha": 0.7, "histtype": "stepfilled", "edgecolor": "k"},
legend_kwargs={"title": "Levels", "loc": "upper left"},
)
apt.pl.label_axes(
ax,
xlabel="Values",
ylabel="Frequency",
title="Histogram with custom colors based on levels\nfrom AnnData",
enumeration="B",
)
apt.pl.save_figure(
fig=fig,
filename="example_histogram.png",
output_dir="./example_outputs",
dpi=300,
transparent=False,
)
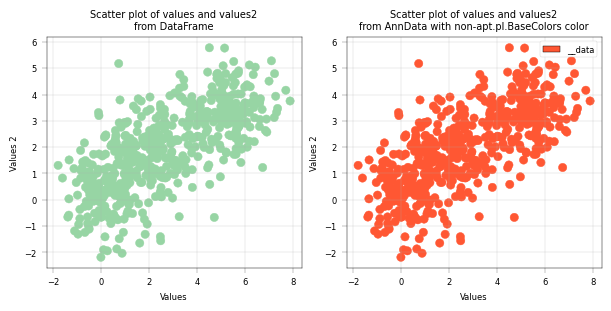
Basic Scatterplot with DataFrame and AnnData#
fig, axm = apt.pl.create_figure(1, 2, figsize=(6, 3))
# Scatterplot based on DataFrame
ax = axm.next()
apt.pl.scatter(
data=example_adata,
x_column="values",
y_column="values2",
color=apt.pl.BaseColors.get("lightgreen"), # Some color from alphapepttools' apt.pl.BaseColors
ax=ax,
)
apt.pl.label_axes(ax, xlabel="Values", ylabel="Values 2", title="Scatter plot of values and values2\nfrom DataFrame")
# Scatterplot based on AnnData
ax = axm.next()
apt.pl.scatter(
data=example_adata,
x_column="values",
y_column="values2",
color="#FF5733", # Some different color that is not in alphapepttools' apt.pl.BaseColors
ax=ax,
legend="auto", # Automatically create a legend
)
apt.pl.label_axes(
ax,
xlabel="Values",
ylabel="Values 2",
title="Scatter plot of values and values2\nfrom AnnData with non-apt.pl.BaseColors color",
)
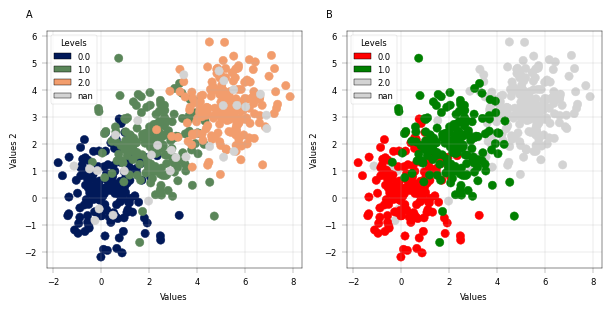
Conveniently plot multiple levels in one scatterplot#
# with multiple colors based on levels
fig, axm = apt.pl.create_figure(1, 2, figsize=(6, 3))
# Automatic coloring
ax = axm.next()
apt.pl.scatter(
data=example_adata,
x_column="values",
y_column="values2",
color_map_column="levels",
ax=ax,
legend="auto",
palette=None,
legend_kwargs={"title": "Levels", "loc": "upper left"},
)
apt.pl.label_axes(
ax,
xlabel="Values",
ylabel="Values 2",
enumeration="A",
)
# Custom coloring
ax = axm.next()
apt.pl.scatter(
data=example_adata,
x_column="values",
y_column="values2",
color_map_column="levels",
ax=ax,
legend="auto",
color_dict={
0.0: "red",
1.0: "green",
}, # Custom color dictionary, 2 is not included. We need to be explicit and exactly match the actual levels.
legend_kwargs={"title": "Levels", "loc": "upper left"},
)
apt.pl.label_axes(
ax,
xlabel="Values",
ylabel="Values 2",
enumeration="B",
)
Heatmap#
–> Not yet implemented
from alphapepttools.pl.colors import BaseColormaps
import anndata as ad
fig, axm = apt.pl.create_figure(1, 1, figsize=(3, 3))
ax = axm.next()
arr = np.random.rand(10, 10) - 0.5
annd = ad.AnnData(
X=arr,
obs=pd.DataFrame(index=[str(i) for i in range(arr.shape[0])]),
)
ax.imshow(annd.X, cmap=BaseColormaps.get("diverging"))
apt.pl.label_axes(
ax,
xlabel="Columns",
ylabel="Rows",
)
Particular attention is paid to continuous colorscales that map to values:#
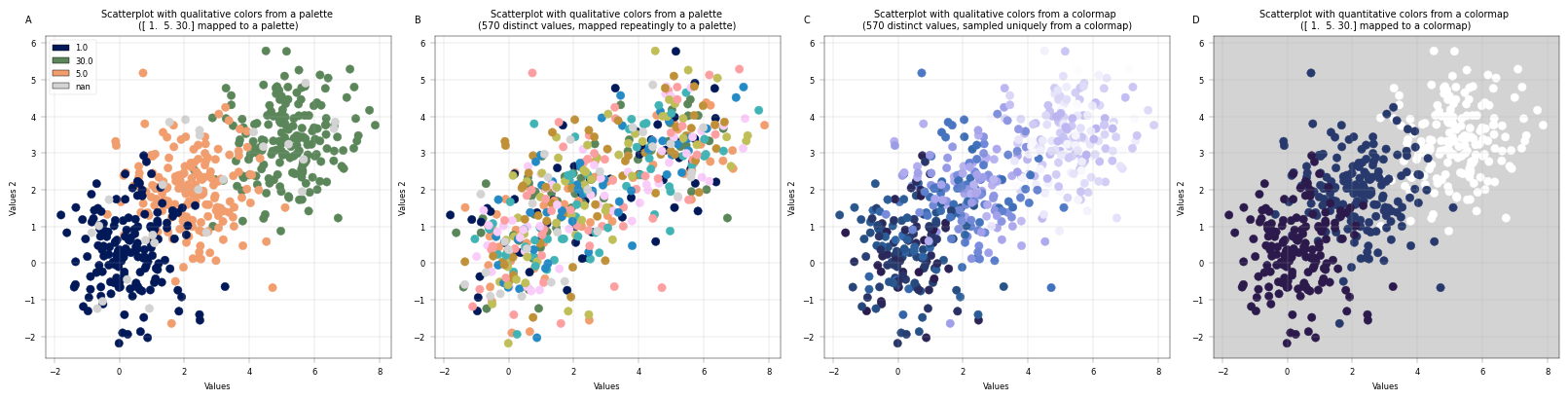
The plots below showcase four different cases that can occur with scatterplots, depending on which value should be colored:
A: Scatterplot with three levels, colored with a qualitative palette
B: Scatterplot with many levels, colored with a qualitative palette - but since the palette is finite, we run into repetitions
C: Scatterplot with many levels, colored with a sequential colormap. This means that each level gets a unique shade of color, but the shades do not translate to values: dark blue is not ‘less’ than light, etc.
D: Scatterplot with three numeric levels that are mapped to a sequential colormap: Now, the difference between the values does matter for coloring - 1. and 5. are dark blue and relatively close together, while 30. is much further apart both numerically and in terms of color.
–> If you want to encode your numerical values in color, supply a numerical column to color_map_column AND a colormap to the palette argument. Any other configuration will not preserve the numerical scale in the colorspace.
# with a large number of levels and automatic shift to squential coloring
fig, axm = apt.pl.create_figure(1, 4, figsize=(16, 4))
# Coloring qualitative levels with a palette
ax = axm.next()
apt.pl.scatter(
data=example_adata,
x_column="values",
y_column="values2",
color_map_column="levels3",
legend="auto",
ax=ax,
palette=None,
)
apt.pl.label_axes(
ax,
xlabel="Values",
ylabel="Values 2",
title=f"Scatterplot with qualitative colors from a palette \n({example_adata.obs['levels3'].dropna().unique()} mapped to a palette)",
enumeration="A",
)
# By default, the standard color palette will just be repeated if there are many distinct values
ax = axm.next()
apt.pl.scatter(
data=example_df,
x_column="values",
y_column="values2",
color_map_column="levels2",
ax=ax,
)
apt.pl.label_axes(
ax,
xlabel="Values",
ylabel="Values 2",
title=f"Scatterplot with qualitative colors from a palette \n({example_adata.obs['levels2'].nunique()} distinct values, mapped repeatingly to a palette)",
enumeration="B",
)
# If we want to avoid color repetition, we can use a sequential colormap instead. If the values are not numeric, this will
# simply assign a distinct color to each level with no particular order.
ax = axm.next()
apt.pl.scatter(
data=example_adata,
x_column="values",
y_column="values2",
color_map_column="levels2",
ax=ax,
palette=apt.pl.BaseColormaps.get("sequential"),
)
apt.pl.label_axes(
ax,
xlabel="Values",
ylabel="Values 2",
title=f"Scatterplot with qualitative colors from a colormap \n({example_adata.obs['levels2'].nunique()} distinct values, sampled uniquely from a colormap)",
enumeration="C",
)
# However, when the values are numerical and we care about their quantitative relationship, we can map them to a colormap.
ax = axm.next()
ax.set_facecolor(apt.pl.BaseColors.get("lightgrey"))
apt.pl.scatter(
data=example_adata,
x_column="values",
y_column="values2",
color_map_column="levels3",
legend="auto",
ax=ax,
palette=apt.pl.BaseColormaps.get("sequential"), # force quantitative mapping of the numerical column to a colormap
)
apt.pl.label_axes(
ax,
xlabel="Values",
ylabel="Values 2",
title=f"Scatterplot with quantitative colors from a colormap \n({example_adata.obs['levels3'].dropna().unique()} mapped to a colormap)",
enumeration="D",
)
plt.show()
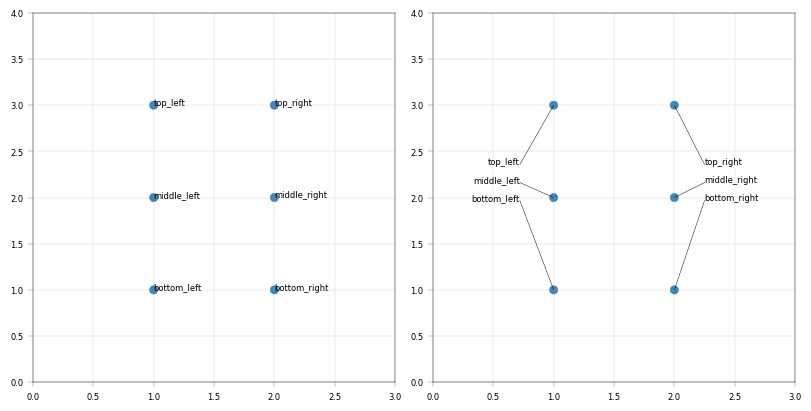
Labelling data with anchors#
A particular challenge of volcanoplots and scatterplots in general is the positioning of labels: When they are attached to the points, they easily overlap. When they ‘dodge’ each other with connectors, plots can become cluttered and volatile. alphapepttools implements an anchor solution: our apt.pl.label_plot function can take x-axis anchors. Each label is stacked above its closest anchor point and connected to the datapoint with a line. This way, many labels can be added while keeping the plot tidy and suitable for miniaturization.
testdata = ad.AnnData(
pd.DataFrame(
{
"x": [2, 1, 2, 1, 2, 1],
"y": [2, 2, 3, 3, 1, 1],
},
index=["A", "B", "C", "D", "E", "F"],
)
)
testlabels = pd.DataFrame(
{
"label": ["middle_right", "middle_left", "top_right", "top_left", "bottom_right", "bottom_left"],
},
index=["A", "B", "C", "D", "E", "F"],
)
testdata = apt.pp.add_metadata(testdata, testlabels, axis=0)
fig, axm = apt.pl.create_figure(1, 2, figsize=(8, 4))
# Labels are extracted from the anndata object
# TODO: change this so that apt.pl.label_plot takes the anndata object directly
label_df = testdata.to_df().join(testdata.obs)
### Label without and with anchors
for x_anchors in [None, (0.72, 2.25)]:
ax = axm.next()
apt.pl.scatter(
data=testdata,
x_column="x",
y_column="y",
ax=ax,
)
label_lines = apt.pl.label_plot(
ax=ax,
data=label_df,
x_column="x",
y_column="y",
label_column="label",
x_anchors=x_anchors,
y_display_start=2.5,
y_padding_factor=10,
)
ax.set_xlim(0, 3)
ax.set_ylim(0, 4)
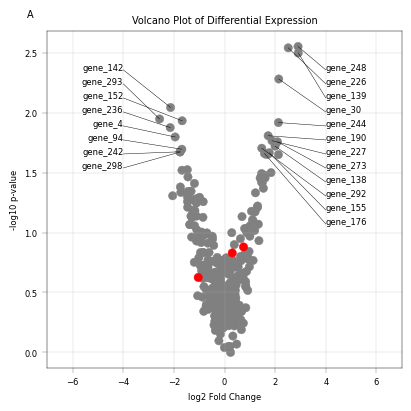
Showcase anchored labels with differential expression data#
# Set up reproducible random number generation
rng = np.random.default_rng(seed=42)
# example data, should be replaced by actual differential expression results from example file
testx = rng.normal(0, 1, 300)
testy = -np.cos(testx) + rng.normal(0, 0.2, 300)
testp = 10 ** -(testy - min(testy))
vp_data = pd.DataFrame(
{
"id": [f"P{10000 + i}" for i in range(300)],
"gene": [f"gene_{i}" for i in range(300)],
"log2fc": testx,
"pval": testp,
"neg_log10pval": -np.log10(testp),
}
)
vp_data.index = vp_data["id"].astype(str)
example_adata_diff = ad.AnnData(
X=vp_data[["log2fc", "pval", "neg_log10pval"]].values,
obs=vp_data[["id", "gene"]],
var=vp_data[["log2fc", "pval", "neg_log10pval"]].columns.to_frame(),
)
# Add some example categorical and point-of-interest annotations
example_adata_diff.obs["diff_exp_status"] = example_adata_diff.to_df()["log2fc"].apply(
lambda x: "upregulated" if x > 1 else ("downregulated" if x < -1 else "unchanged")
)
example_adata_diff.obs["pathway"] = rng.choice(
["pathway_A", "pathway_B", "pathway_C", "pathway_D", "pathway_E"], size=example_adata_diff.n_obs
)
example_adata_diff.obs["poi_status"] = rng.choice(["poi", "background"], size=example_adata_diff.n_obs, p=[0.01, 0.99])
# Visualize volcanoplot
fig, axm = apt.pl.create_figure(1, 1, figsize=(4, 4))
ax = axm.next()
top_n = 20
# Add selected color column
selected_genes = ["gene_0", "gene_1", "gene_2"] # example genes to highlight
example_adata_diff.obs["color"] = example_adata_diff.obs["gene"].apply(
lambda x: "red" if x in selected_genes else "gray"
)
apt.pl.scatter(
ax=ax,
data=example_adata_diff,
x_column="log2fc",
y_column="neg_log10pval",
color_column="color",
)
# Extract points to label
label_data = (
example_adata_diff.to_df().join(example_adata_diff.obs).sort_values("neg_log10pval", ascending=False).head(top_n)
)
apt.pl.label_plot(
ax=ax,
data=label_data,
x_column="log2fc",
y_column="neg_log10pval",
label_column="gene",
y_display_start=2.5,
y_padding_factor=6,
x_anchors=[-4, 4],
)
apt.pl.label_axes(
ax,
xlabel="log2 Fold Change",
ylabel="-log10 p-value",
title="Volcano Plot of Differential Expression",
enumeration="A",
)
ax.set_xlim((-7, 7))
(-7.0, 7.0)
Layering of plot elements#
In order to show multiple annotation layers in a plot, it can be necessary to specify plot “layers”: Consider the case of a volcanoplot where points are colored according to their state “upregulated”, “unchanged”, “downregulated” in the “diff_exp” column, but there also is a set of proteins annotated as belonging to pathway “A” in the “pathway” column. Furthermore, there could be a handful of proteins of interest annotated with “yes” in the “poi” column. The challenge is to properly layer these scatterplots - considering that points may “belong” to multiple categories, i.e. “downregulated” (differential expression) + “A” (pathway) + “yes” (POI) at once. To remove all of this complexity, we introduce the layered_plot, which offers an intuitive interface to build complex visualizations.
# Specify a custom color dictionary for the categories we want to color
color_dict = {
"upregulated": apt.pl.BaseColors.get("red"),
"downregulated": apt.pl.BaseColors.get("blue"),
"unchanged": apt.pl.BaseColors.get("grey"),
"poi": apt.pl.BaseColors.get("black"),
"pathway_A": apt.pl.BaseColors.get("purple", lighten=0.5),
}
# In order to avoid repeating instructions for each layer, we can summarize the parameters for the whole plot in a configuration
layered_plot_config = apt.pl.make_scatter_config(
data=example_adata_diff, # all layers use the same data and numeric columns
x_column="log2fc",
y_column="neg_log10pval",
scatter_kwargs={"alpha": 0.7, "s": 30}, # make the points slightly transparent and set a good size
)
# Define layers: each layer is a tuple of (column to filter on, value to select, color key, optional plotting kwargs)
plot_layers = [
(
"poi_status",
"poi",
"poi",
{"scatter_kwargs": {"marker": "^", "s": 200}},
), # this layer gets custom scatterplot settings kwargs
("pathway", "pathway_A", "pathway_A"),
("diff_exp_status", "upregulated", "upregulated"),
("diff_exp_status", "downregulated", "downregulated"),
("diff_exp_status", "unchanged", "unchanged"),
]
# Visualize the plot with layers
fig, axm = apt.pl.create_figure(1, 1, figsize=(6, 6))
ax = axm.next()
apt.pl.layered_plot(
ax=ax,
base_config=layered_plot_config,
layers=plot_layers,
color_dict=color_dict,
ylims=(0, 3),
xlims=(-3, 4.5), # leave some space for labels on the right side
)
# Add a legend to explain the layers
apt.pl.add_legend_to_axes(
ax,
levels=color_dict,
loc="upper left",
)
# Label axes
apt.pl.label_axes(
ax,
xlabel="log2 Fold Change",
ylabel="-log10 p-value",
title="Layered Volcano Plot of Differential Expression",
)
# Label the points of interest
label_data = example_adata_diff.to_df().join(example_adata_diff.obs)
poi_label_data = label_data[label_data["poi_status"] == "poi"]
apt.pl.label_plot(
ax=ax,
data=poi_label_data,
x_column="log2fc",
y_column="neg_log10pval",
label_column="gene",
y_display_start=0.3, # start labels in the lower part of the plot
y_padding_factor=2, # find good vertical spacing for labels
x_anchors=[3], # anchor to the right side
)
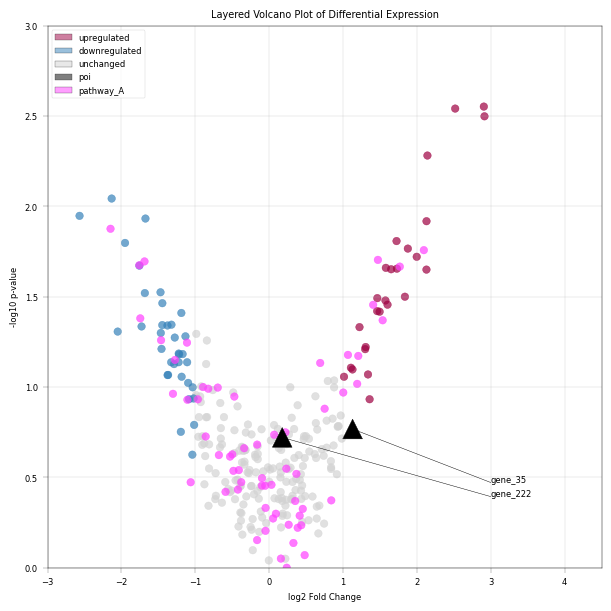
–> Notice how pink points overlay rad/blue/grey ones, but are overlayed by black triangle markers. This way, highlighting hierarchy can be precisely controlled.
Bar, Box and Violinplot#
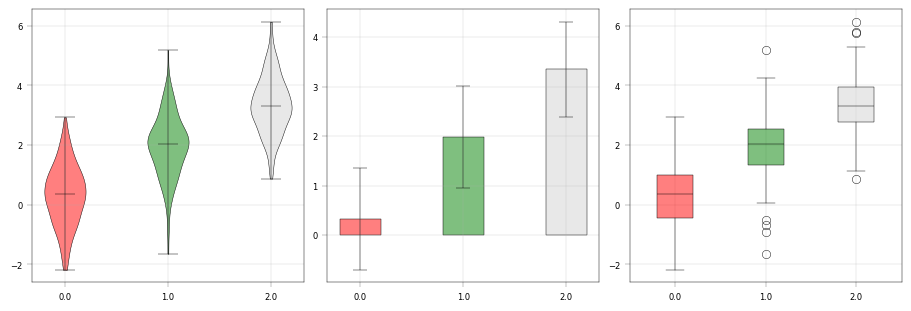
These are really just different views of the same thing - group-wise quantities plots. alphapepttools enables visualization of data here in two modes: either long-data based where there is a grouping column and a value column, or wide-data based where the columns are directly shown. This is crucial for proteomics analyses: sometimes, we want to see e.g. the abundance of one protein in different metadata brackets, e.g. disease and healthy (long data case), sometimes we just want an overview over our protein abundances (wide data case).
A key feature is that columns can be selected seamlessly from obs and X, since frequently grouping information is stored in obs while numerical values are in X.
# Long data format usage: grouping and values column --> notice that columns can be selected from X and obs
fig, ax = apt.pl.create_figure(1, 3, figsize=(9, 3))
color_dict = {
0.0: "red",
1.0: "green",
} # Custom color dictionary, 2 is not included. We need to be explicit and exactly match the actual levels.
apt.pl.violinplot(
ax=ax.next(),
data=example_adata,
grouping_column="levels",
value_column="values2",
color_dict=color_dict,
)
apt.pl.barplot(
ax=ax.next(),
data=example_adata,
grouping_column="levels",
value_column="values2",
color_dict=color_dict,
)
apt.pl.boxplot(
ax=ax.next(),
data=example_adata,
grouping_column="levels",
value_column="values2",
color_dict=color_dict,
)
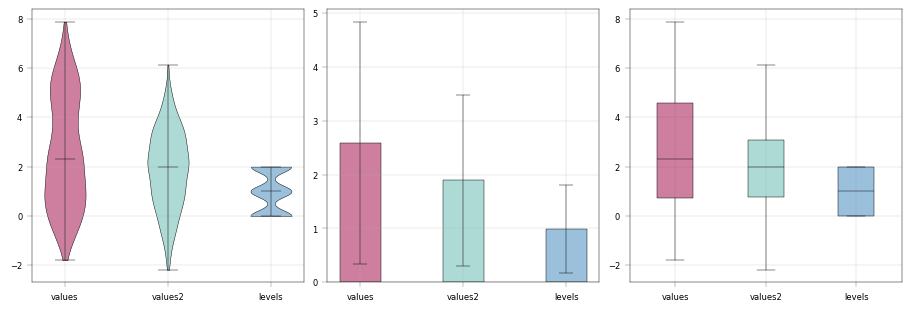
# Wide data usage: direct columns --> notice that columns can be selected from X and obs
fig, ax = apt.pl.create_figure(1, 3, figsize=(9, 3))
color_dict = {
"values": apt.pl.BaseColors.get("red", alpha=0.5),
"values2": apt.pl.BaseColors.get("green", alpha=0.5),
"levels": apt.pl.BaseColors.get("blue", alpha=0.5),
}
apt.pl.violinplot(
ax=ax.next(),
data=example_adata,
direct_columns=["values", "values2", "levels"],
color_dict=color_dict,
)
apt.pl.barplot(
ax=ax.next(),
data=example_adata,
direct_columns=["values", "values2", "levels"],
color_dict=color_dict,
)
apt.pl.boxplot(
ax=ax.next(),
data=example_adata,
direct_columns=["values", "values2", "levels"],
color_dict=color_dict,
)
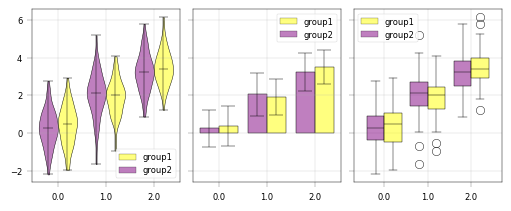
Grouped box, bar and violin plot:#
In order to compare conditions, it can be useful to group comparisons (e.g. to visualize treatment vs. control for each protein/gene/precursor in a list). The subgroups argument in the box/bar/violin plot functions handles this kind of grouping:
# Randomly assign to group 1 or 2 across all obs
example_adata.obs["subgroup"] = rng.choice(["group1", "group2"], size=example_adata.n_obs)
# Long data format usage: grouping and values column --> notice that columns can be selected from X and obs
fig, ax = apt.pl.create_figure(1, 3, figsize=(5, 2), subplots_kwargs={"sharey": True})
color_dict = {
"group1": "yellow",
"group2": "purple",
} # Custom color dictionary, 2 is not included. We need to be explicit and exactly match the actual levels.
apt.pl.violinplot(
ax=ax.next(),
data=example_adata,
grouping_column="levels",
value_column="values2",
color_dict=color_dict,
subgroup_column="subgroup",
legend="auto",
)
apt.pl.barplot(
ax=ax.next(),
data=example_adata,
grouping_column="levels",
value_column="values2",
color_dict=color_dict,
subgroup_column="subgroup",
legend="auto",
)
apt.pl.boxplot(
ax=ax.next(),
data=example_adata,
grouping_column="levels",
value_column="values2",
color_dict=color_dict,
subgroup_column="subgroup",
legend="auto",
)
Advanced scatterplots: Categorical values#
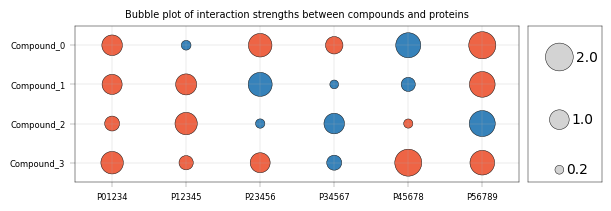
Frequently, data is visualized with one or two categorical axes, e.g. a “bubble plot” of interaction values, with point size & color encoding interaction strength and direction:
rng = np.random.default_rng(seed=42)
# Interaction dataset where proteins show different interaction strengths with compounds
interaction_dataset = pd.DataFrame(
data=rng.random((4, 6)) * 4 - 2,
columns=[f"P{''.join([str(i) for i in range(j, j + 5)])}" for j in range(6)],
index=[f"Compound_{i}" for i in range(4)],
)
interaction_dataset["compound"] = interaction_dataset.index
# Order in opposite order of compound to have compound 0 on top
interaction_dataset = interaction_dataset.iloc[::-1]
# Melt the dataset into long format for plotting
interaction_dataset_long = interaction_dataset.melt(
id_vars=["compound"], var_name="protein", value_name="interaction_strength"
)
# Map direction to color
interaction_dataset_long["direction"] = interaction_dataset_long["interaction_strength"].apply(
lambda x: "up" if x > 0 else "down"
)
color_dict = {
"up": apt.pl.BaseColors.get("orange"),
"down": apt.pl.BaseColors.get("blue"),
"neutral": apt.pl.BaseColors.get("lightgrey"),
}
# Generate figure and axis
fig, axm = apt.pl.create_figure(1, 2, figsize=(6, 2), gridspec_kwargs={"width_ratios": [6, 1]})
# Visualize heatmap as bubble plot
ax = axm.next()
apt.pl.scatter(
ax=ax,
data=interaction_dataset_long,
x_column="protein",
y_column="compound",
color_map_column="direction",
color_dict=color_dict,
scatter_kwargs={
"s": interaction_dataset_long["interaction_strength"].abs() * 200,
"edgecolor": "black",
},
order="original", # keep the original order of the data, which is the same as the order in the heatmap
# empirical limits to contain points within the plot area
xlim=(-0.5, len(interaction_dataset.columns) - 1.5),
ylim=(-0.5, len(interaction_dataset.index) - 0.5),
)
apt.pl.label_axes(
ax,
title="Bubble plot of interaction strengths between compounds and proteins",
)
# Show reference sizes for the bubbles
legend_data = pd.DataFrame(
{
"position": [1, 1, 1],
"interaction_strength": [0.2, 1, 2],
"direction": ["neutral", "neutral", "neutral"],
}
)
# some formating
ax = axm.next()
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.set_xticks([])
ax.set_yticks([])
ax.grid(False) # noqa: FBT003
# scatterplot for legend
legend_data["position"] = legend_data["position"] + 0.2
apt.pl.scatter(
ax=ax,
data=legend_data,
x_column="position",
y_column="interaction_strength",
color_map_column="direction",
color_dict={
"up": apt.pl.BaseColors.get("orange"),
"down": apt.pl.BaseColors.get("blue"),
"neutral": apt.pl.BaseColors.get("lightgrey"),
},
scatter_kwargs={
"s": legend_data["interaction_strength"].abs() * 200,
"edgecolor": "black",
},
xlim=(0.6, 2),
ylim=(0, 2.5),
order="original",
)
# add numbers
legend_data["position"] = legend_data["position"] + [
0.12,
0.22,
0.32,
] # move the labels slightly to the right of the points for better visibility
apt.pl.label_plot(
ax=ax,
data=legend_data,
x_column="position",
y_column="interaction_strength",
label_column="interaction_strength",
label_kwargs={"ha": "left", "va": "center", "fontsize": 10},
)